Researcher:Ryunosuke Daido
| Division | Music Interaction Group, Advanced Technology Research Department, Research & Development Division |
|---|---|
| Details of Work | Research and development of singing voice synthesis technology using AI and signal processing |
| Field of Study | Electrical and Communication Engineering |
| Year Joined Yamaha | 2012 |
Current Work and Research
I have been working on research and development of the singing voice synthesis technology, VOCALOID® ever since I joined Yamaha.
VOCALOID® is a singing voice synthesis technology that Yamaha announced in 2003. When I joined Yamaha in 2012, I was first assigned to the product development division, where I worked on developing smartphone applications for music production beginners, leveraging the existing VOCALOID® core technology. After that, I transferred to the Research & Development Division, where I have been in charge of research and development of the core singing voice synthesis technology itself to this day.
The original VOCALOID® uses signal processing techniques such as pitch shifting and timbre interpolation to seamlessly splice together pre-recorded samples of human voices — that is, very short waveforms — to achieve singing voice synthesis. This is an extremely powerful technology that enables music creators to assign various melodies and expressions based on the voices of distinctive singers and voice actors, creating entirely new music. I have been involved in research and development aimed at expanding the expressiveness of VOCALOID4 and later versions — for example, a feature that enables singing expressions using vocal techniques such as growl, achieved through morphing of specially recorded expression samples separate from the standard samples.
In 2018, we developed and announced a new AI-powered singing voice synthesis technology called “VOCALOID:AI®.” The advantage of using AI is that it can reproduce natural expressions as if the original singer were interpreting and performing the score themselves. For example, it can reproduce the singer’s use of different timbres depending on combinations of lyrics and pitch range, as well as pitch movements such as scooping and vibrato shaped by the surrounding melodic context, all learned from the original singer’s vocal data. This has made it possible to create music that directly leverages the attractive and wide-ranging musical expressions inherent to human singers.


Currently, my research focus is on VOCALOID:AI®, but we value and utilize both the original VOCALOID® and VOCALOID:AI® technologies. In practice, we are advancing our research and development of cutting-edge technology by combining signal processing and AI techniques in an integrated manner.
AI-based singing voice synthesis is a new technology, and it is no exaggeration to say that its potential is truly limitless, with a vast range of possible applications. We are not simply aiming to develop a singing voice synthesis technology that automatically reproduces the original singer’s voice. The true protagonists are the creators who use the singing voice synthesizer to make music. We want to further evolve and deliver our singing voice synthesizer as an indispensable tool for music creators around the world — one that empowers them to create and share their own unique, distinctive, and compelling new music.
Rather than solely replicating the voice of a human singer, what kinds of sounds can a singing voice synthesizer produce in response to a creator’s imagination? And what operations allow creators to achieve those sounds? — These are the questions we discuss and examine with our internal team members and external music creators. We then devise implementation methods using signal processing and AI technology, and build working systems that can actually be touched and heard. That is our work.
Why I Chose Yamaha
At university, I majored in Electrical and Communication Engineering. I belonged to a lab that dealt with speech and audio in the context of communication technology, where I conducted research on karaoke scoring. Since I love singing, I was a member of the university choir, and I also sang tenor in an amateur opera company.
Studying communication engineering and speech science at university involves dealing with quite difficult theories and mathematical formulas. When I first started studying in class, I would feel dismayed just looking at the integral notation of Fourier transforms and convolutions. There were times when I couldn’t see the practical value of studying such difficult material, and I struggled with motivation. Nevertheless, once I joined the lab and began working with singing voices, things became enjoyable. I found it fascinating to decipher the mathematical formulas in academic papers and implement them as programs. And what I found most enjoyable of all was when I implemented my research results as a smartphone application and demonstrated it at academic conferences — singing myself as part of the demonstration.
The academic knowledge of audio signal processing and the implementation skills to turn that knowledge into actual applications are strengths I cultivated during my student years. When I thought about where I could put these strengths to work, Yamaha was where I decided to go.
There are other manufacturers and software development companies that deal with audio equipment and music-related products besides Yamaha, but I was particularly drawn to Yamaha among these options. It wasn’t just because Yamaha is the developer of VOCALOID®. It’s difficult to explain precisely, but I felt that the entire company was driven by a passion for pursuing the excitement people feel at the moment they create or listen to sound — a kind of joy that cannot necessarily be measured in numbers. During my job search, I met and spoke with Yamaha employees multiple times at internships and academic conferences, and I picked up on that atmosphere. Even now, after more than ten years at the company, that impression hasn’t changed. Sometimes we have discussions where our enthusiasm runs a little ahead of us, and when an experiment produces a great sound, we celebrate together with unbridled excitement — before even looking at the numbers. It is precisely within this atmosphere and sense of shared purpose that I find genuine enjoyment in the work of calmly constructing theories and solving equations.
Recent Research Project Examples
VOCALOID β Studio
VOCALOID β-Studio is a proof-of-concept project for singing voice synthesis that we conducted in 2024. We released a limited-time plugin called “VX-β” for music production software (Digital Audio Workstation: DAW), equipped with new singing voice synthesis technology still at the research stage. Over approximately six months, thousands of creators tried it out. During the proof-of-concept period, a variety of new musical works were created, and we received extensive feedback on the user experience from many creators. We are currently using this to further improve upon the base technology.
How can we enable even more music creators around the world to use singing voice synthesis and produce music that expresses their own creative individuality? The answer we presented through the VOCALOID β-Studio project was to create a singing voice synthesizer capable of real-time, intuitive control. Conventional singing voice synthesizers, due to various technical constraints, had significant time lag between inputting a score and hearing the synthesized singing voice. Moreover, giving the synthesized singing voice the expressiveness desired by the creator required writing detailed values for multiple parameters. So what we built was a new singing voice synthesis plugin for DAWs that synthesizes singing voice in real time and allows creators to instantly apply singing expressions — such as “powerfulness” — simply by turning a knob.

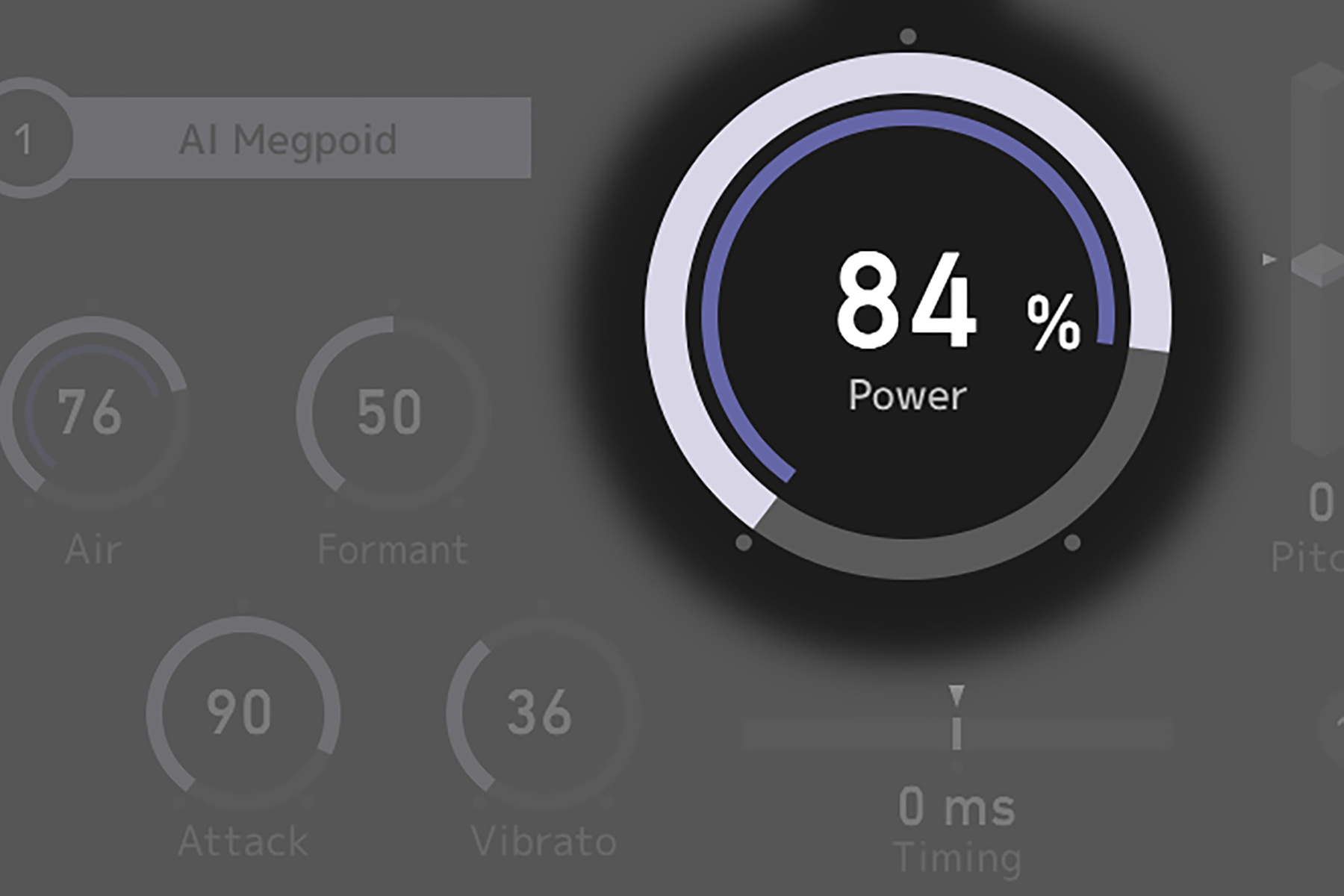
Rather than pursuing only fidelity to the original singer’s voice, we took a holistic view of the experience of creators generating music from their own sensibilities, and brought the tools for that experience into reality. That is what I consider the key point of this project. Rather than treating singing voice synthesis and the user interface as separate concerns, we envisioned the actual moments when creators produce sound in real music production, and carried out fundamental improvements at the structural level of deep neural networks and signal processing blocks in an integrated manner with user interface R&D. Through this approach, I believe we were able to propose one vision of what near-future music production using AI and signal processing technology could look like.
Additionally, one of the exciting aspects of this project is that it was realized through the collaboration of many colleagues within the company. At one point, we developed a prototype that would become the basis for VX-β and held an internal demonstration. This sparked interest from members across many departments within the company who had not previously been directly involved with singing voice synthesis. By cooperating across development, planning, public relations, and other areas, we were able to establish the optimal framework for delivering this technology to creators. Furthermore, this led to a technical collaboration with Steinberg — a Yamaha group company and the developer of the DAW Cubase — enabling us to achieve advanced integration between singing voice synthesis and the DAW. While the project has formally concluded, we continue to work with the colleagues who came together at that time to pursue further improvements. I believe that one of the great rewards of R&D at Yamaha is the ability to research and develop new technology, demonstrate its potential, rally like-minded colleagues, and together build the momentum to deliver it to music creators and players around the world.
Narikiri Microphone®
Narikiri Microphone® (literally “Become-Your-Idol Microphone”) is a proof-of-concept project using voice conversion technology, conducted from 2022 to 2024. For a limited time, we provided an experience where users could sing at karaoke boxes equipped with our system, having their voice converted in real time so they could sing as if they were their favorite artist.
Singing is one of the forms of music that many people, whether professional or amateur, can enjoy. Until this project, we had primarily conducted R&D on singing voice synthesis as a technology for music creators, but it was through that process that we developed this voice conversion technology as a derivative technology. This technology also gained momentum through an internal demonstration, which led to in-depth discussions with our marketing department. Ultimately, it culminated in a collaboration with a well-known artist and a proof-of-concept experiment at actual commercial karaoke venues.

In this project, it was extremely important that we identified the karaoke box as the application setting for the technology and established a clear use case: becoming your favorite artist and having a blast in that space. There were both social and technical considerations behind this.
First, the social aspect. Voice conversion technology — whether for singing or speaking voice — is an extremely interesting technology capable of creating expressions with diverse voices and nuances. However, it also carries risks of misuse and concerns regarding rights, making it a technology where finding appropriate applications can be challenging. Simply proposing it as a voice conversion technology leaves the question of who would use it and how unanswered, which would make the providers of the voice data feel uneasy. In this case, having the karaoke box as a defined setting clarified the purpose: fans and a wider audience could “become” the artist and enjoy themselves on the spot. This made it possible to bring about a collaboration that the artists themselves could also be happy about.
Next, the technical aspect. Through this project, we were able to improve the latency of our voice conversion technology — the delay between when the singing voice is input and when the converted voice is heard — and significantly enhance its robustness against accompaniment bleed-through. In fact, the first system we built was completely unusable when we tested it on-site at the karaoke box. There were two problems: the latency was too high, making it very difficult to sing, and the karaoke accompaniment bleeding into the microphone degraded the conversion quality. We were taken aback by how different the real-world conditions were from our usual research environment, but we made major technical improvements before the start of the proof-of-concept experiment and achieved a quality that allowed people to truly enjoy singing.
Regarding the accompaniment bleed-through issue, at one point someone even suggested putting up a sign saying “Please don’t turn the accompaniment volume up too high.” However, part of the fun of karaoke is being able to sing at a volume you can’t produce at home. Sacrificing enjoyment to accommodate the technology would defeat the purpose. Precisely because we had the clear objective of becoming your favorite artist and having a blast, we insisted on making it work with normal, loud accompaniment levels, and solved the problem through deep neural networks and signal processing technology.
These performance metrics are ultimately evaluated quantitatively using numerical indicators such as latency in milliseconds and SNR in decibels, and improvements are made accordingly. However, it is because we ourselves understand — based on firsthand experience — what serves as the basis for setting those numerical targets and how much fun the experience becomes when those targets are met, that we were able to achieve dramatic performance improvements in a short period and deliver an experience that many people could genuinely enjoy.
Future Goals in the Age of AI
We want to create tools that enable music creators around the world to produce and share their own unique, distinctive, and compelling new music. I sense enormous potential in further advancing AI technology to expand creators’ creativity and to enable even those new to music production to participate in the process.
There are various directions and evaluation criteria for music production using AI technology, but I personally want to prioritize evoking the thrill creators feel at the moment they produce sound and music, and the confidence that comes from expressing music that is uniquely their own. This is because those feelings fuel the passion for sharing music with others and the motivation to create again. The real-time expression control technology we offered experimentally through the VOCALOID β-Studio project showed real promise as a means of delivering this sensation to creators. Using the results of such proof-of-concept experiments as a springboard, I want to pursue the development of AI technology that is deeply connected to user experience — not only in singing voice synthesis, but across various elements of music production.
Qualities such as excitement and confidence are not something that can be simply measured by accuracy rates or error metrics, making them difficult to evaluate. On the other hand, the approach of obtaining practical feedback from many users in real environments through proof-of-concept experiments has proven extremely effective and is reliably leading to the next proposals for new experiences. Going forward, my vision for R&D is to systematize this new-era R&D process, execute it in rapid cycles, and pioneer new music production experiences powered by cutting-edge AI technology.

