AI Sound Synthesis Technology
VOCALOID:AI™, AI musical instrument sound synthesis technology

What is AI Sound Synthesis Technology?
The term “sound synthesis technology” refers to the technology of creating (synthesizing) the sounds that make up music, such as musical instruments and singing voices. For example, this technology is now used in many digital musical instruments such as electric pianos or synthesizers to create a variety of sounds, which are sometimes realistic, sometimes electric. The AI sound synthesis technology has been developed by introducing brand new artificial intelligence (AI) technology, making it possible to create not only realistic sounds but also nuances of performance that make it sound as if a human were really playing.
The first AI sound synthesis technology developed by Yamaha was VOCALOID:AI™ for singing voices, announced in 2019. After that, we further applied it to musical instrument sound synthesis and developed the AI musical instrument sound synthesis technology, which we announced in 2021.
VOCALOID:AI™(AI Singing Synthesis Technology)
VOCALOID is a proprietary singing voice synthesis technology that Yamaha has been researching and developing for many years. This technology, which allows users to input notes and lyrics and have them sung as desired, has been incorporated in our music production software (that is also named VOCALOID) and is widely used in the music production scene up to the latest version, VOCALOID5. VOCALOID:AI™, in particular, is a new technology that has evolved by introducing AI technology. VOCALOID:AI™ is a totally new vocal synthesizer that EXPRESSES ITSELF.
When a user gives VOCALOID:AI™ notes and lyrics, it not only traces the notes and lyrics, but also determines the nuances to be performed on the notes (for example, how to select timbres, how to connect notes, how to apply vibrato, etc.), creating a lively voice that sounds like a real singer. What makes this technology different from conventional sound synthesis technology is that the synthesizer makes its own expression, sometimes in a way that the creator would never have thought of. Being inspired from the AI, creators may be able to expand their own perspective of expression when they create music. This relationship between creators and synthesizers is more like that between a director and a singer than that between a person and a tool.
The process of VOCALOID:AI™ can be roughly divided into two phases: the training phase and the synthesis phase.
Basic Concept of Training the AI
In the training phase, VOCALOID:AI™ learns the timbre, singing style, and other characteristics of a target human singer’s voice with the technique of deep learning. VOCALOID:AI™ can then create a singing voice that includes the singing expressions and nuances of the original singer for any arbitrary melody and lyrics.
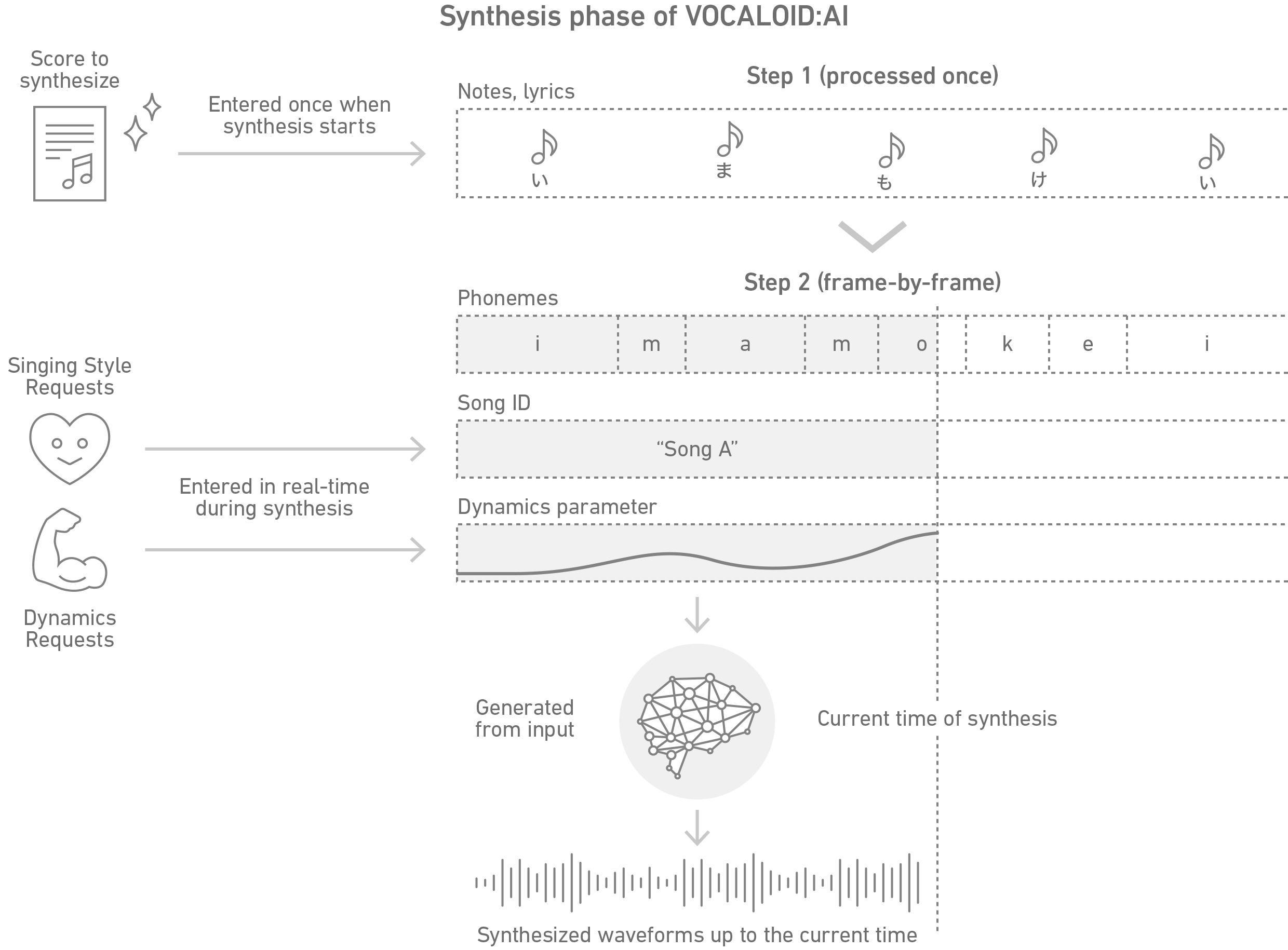
The first step of the training is to extract the acoustic features. Timbre and pitch information are extracted from the singing voice, and timing deviation information is extracted from the paired data of the singing voice and the score. The aim of the training phase is to make the AI learn the tendency of correspondence between the acoustic features and the score information (notes and lyrics). However, some elements of the human singing voice can not be determined from the sequence of notes and lyrics alone. Even if the exact same melody and lyrics are given, a variety of timbres could be applied, depending on the singer’s singing style, the genre of the song, and the dynamics used by the singer. To solve this, a couple of auxiliary features that could represent such singing styles are explicitly extracted from the training data and fed into the AI. The dynamics parameter is calculated from the singing voice itself, and the song ID information is used to represent a singing style that could be related to each song.
During this training phase, it takes a few hours or maybe a few days for the AI to learn the original singer’s performance by iterating its computation millions of times.

VOCALOID:AI has two remarkable features in the following synthesis phase.
Feature 1: Requesting Singing Expression to an AI Singer
While VOCALOID:AI™ automatically applies singing nuances to the synthesized sounds, they do not always match the expression that the human creators really want. We believe that it is very important to make it possible for the AI synthesizer to receive the creator’s musical intention, expecting the AI to SUPPORT humans as they express themselves, not TAKE AWAY human creativity. VOCALOID:AI™ allows users to make requests regarding musical expression in its singing. The song ID information and the dynamics parameter introduced in the training phase are used here. Users can make requests such as “with the atmosphere of a certain song” by specifying the ID of a song used for training, “with a slightly strong nuance” by explicitly giving the dynamics parameter to the AI. VOCALOID:AI™ responds to the request by changing the singing voice with respect to nuances such as phrasing, vibrato, deepness, and breathing, by estimating how the original would have sung the song if requested to do so. As a result, users are able to create their own vocal tracks in a very intuitive way, just as a musical director instructs a singer in the real world.
Feature 2: Real-time Interaction with an AI Singer during a Performance
VOCALOID:AI™ receives requests for singing expression in real-time while the synthesis process is going on. This feature, which allows users to create music as if they were actually interacting with a virtual singer on a stage, is an especially important part of Yamaha’s AI sound synthesis technology.
The synthesis phase can be roughly divided into two steps. In the first step, the information of the entire score is input into the system. This allows the AI to understand information such as “this song consists of such structures,” “each note connects to such kinds of notes,” etc. The second step is processed frame-by-frame (e.g., 100 times per second) as the AI decides what sound to generate at that moment, given a song ID and the dynamics parameter. Each of these steps can be compared to the following steps in human singing: the first step corresponds to reading, interpreting, and understanding the music, and the second step to singing a song aloud.
AI Musical Instrument Sound Synthesis Technology
We have developed an AI instrument sound synthesis technology by adapting VOCALOID:AI™ technology to a wide range of instrument sounds. Currently, the AI can realize lively performances of wind instruments such as saxophones, trumpets, flutes, clarinets, and oboes in a similar way to singing voices. This is also a completely new type of musical instrument sound synthesis technology that EXPRESSES ITSELF. Given a score, the synthesizer determines the nuances of expression by referring to the sequence of notes, then synthesizes the sound (waveform) of the instrument, including vibrato, crescendo, decrescendo, and so on as if it were really played by a human. This makes it much simpler for users to create a full-fledged wind instrument performance track than giving detailed music expression parameters. The AI musical instrument sound synthesis technology also has the same two features as VOCALOID:AI.
Feature 1: Requesting Performance Expression to an AI Performer
Given requests such as “with the atmosphere of a certain song” or “with a slightly powerful nuance,” the AI synthesizes a waveform by estimating how the original performer would play if such requests were actually given. Depending on how the AI is trained, it could be possible to request a genre, such as “bossa nova style” or “funk style,” instead of specifying the name of a song. (This is also the case with VOCALOID:AI™.)
Feature 2: Real-time Interaction with an AI Performer during a Performance
After having the score of the entire piece read in advance, it is possible to input requests for performance expression in real-time while the synthesis process is going on.
The AI sound synthesis technology has a strong sense of having a virtual AI performer play an instrument. Therefore, rather than using it like a conventional synthesizer where users play the keys in real-time, its strength lies in the way the virtual AI performer and the user interact with each other to create music. For example, it is particularly useful in situations where human instrumentalists and AI performers are in session, or in DTM-based music production.
Applications
AI Artist Stage


Since June 2021, the “AI Artist Stage: Creating Music with AI” exhibit has been open to the public at the “Innovation Road” corporate museum at Yamaha’s headquarters in Hamamatsu City, Shizuoka Prefecture, where visitors can experience VOCALOID:AI™ and the AI musical instrumental sound synthesis technology. Here, visitors can select either an AI singer or an AI saxophonist, and experience playing a song with the AI by requesting dynamics in real-time through a dedicated performance expression sensor.

“Bringing Hibari Misora Back to Life with AI” Project
The Japan Broadcasting Corporation (NHK) launched a project to realize the wishes of fans who wanted to see the late and legendary singer Hibari Misora again, using the latest technology. In this project, VOCALOID:AI™ was used to synthesize the singing voice of the new song “Arekara” (“Ever since then”), produced by Yasushi Akimoto. After training the AI with Hibari Misora’s past songs left by the record company, the song “Arekara” was sung according to the direction provided by producer Yasushi Akimoto. Then the song was performed at a concert in front of about 200 of her enthusiastic fans. The event was broadcast on the documentary program “NHK Special” on September 29, 2019, and drew a great response.

Featured article : “Bringing Hibari Misora Back to Life with AI” Project (Japanese)